生成AI の嘘を初心者が見抜く たった1つの方法
生成AI の出力を信じていいか、技術ゼロで見抜く方法。米弁護士5,000ドル制裁・Air Canada 裁判敗訴・Apple Intelligence 誤要約の3事件から学ぶ、嘘の出やすい7型と『たった1つの検証法』。シリーズ完結篇。

AI が答えを返してくれた時、「これ本当かな?」と一瞬迷うこと、ありませんか。
まわりでよく聞くのが、ChatGPT で調べた内容をそのまま会議資料に貼って、上司に「これ本当?」と聞かれて答えに詰まる、という話です。気持ちは分かる。AI の文章は理路整然としていて、本人ですら「どこが嘘か」分からない。
ただ事例を集めていくと、米国の弁護士が ChatGPT に作らせた架空判例6件を法廷に提出して5,000ドル制裁を受けた事件(2023年・Mata v. Avianca)、Air Canada のチャットボットが間違った案内をして会社が裁判で敗訴した事件(2024年)、Apple Intelligence の通知要約が BBC ニュースを「容疑者が自殺した」と誤って要約した事件(2024年)── 専門家でも大企業でも、検証を怠ると簡単にやらかしている。
結論を先に言うと、たった1つの方法でほぼ防げる。
3分で読めて、明日のメール返信から使えます。
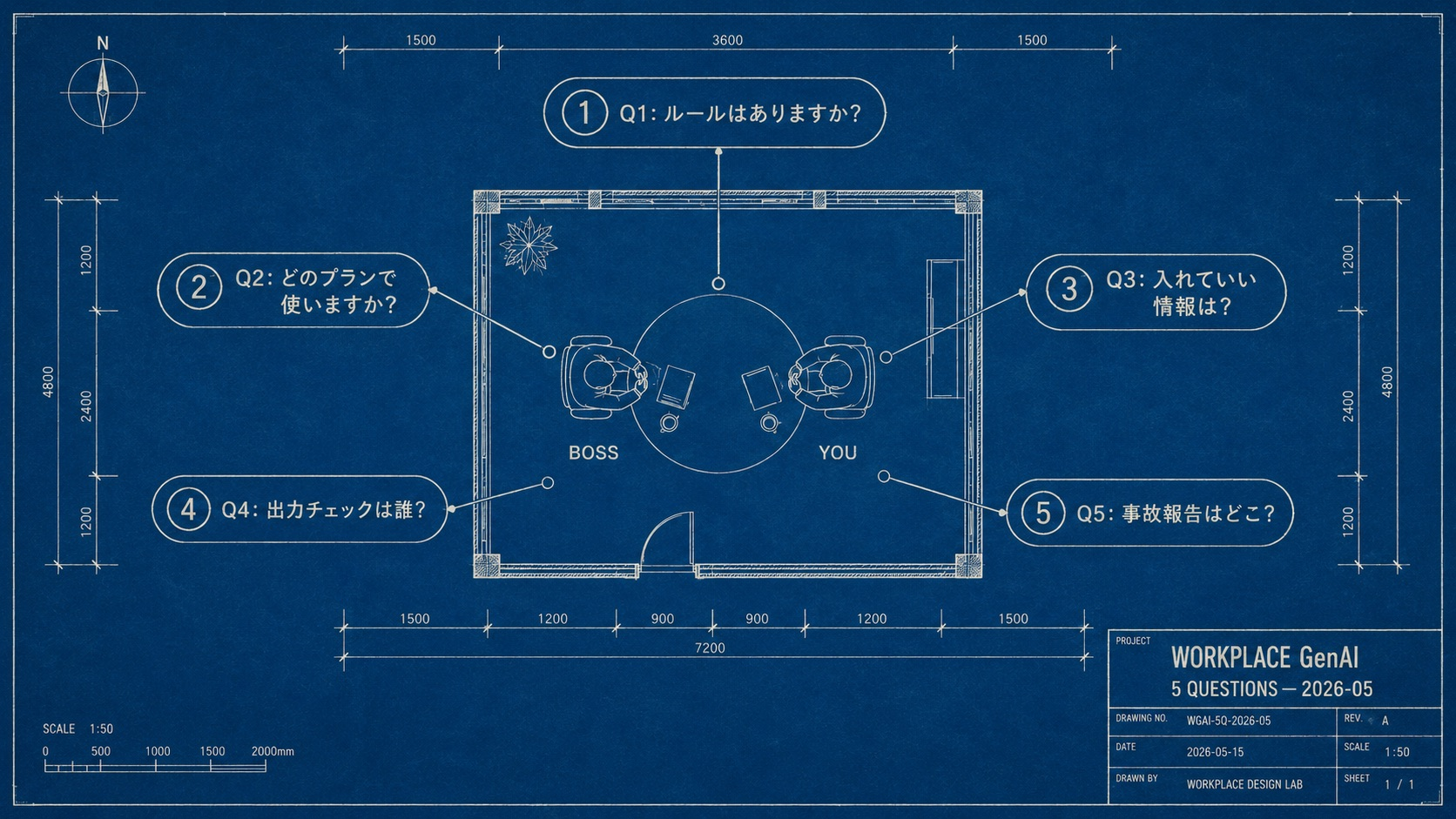
このシリーズについて 「AI を仕事で使う前に知っておくこと」シリーズ 第5弾・最終回 です。1〜4弾は「入れる側」の話(事故対応3手順 / 個人利用20ケース / 漏れ方5経路 / 仕事編5問)。この記事は「出てくる側」── AI の答えを信じる前の検証法を扱います。
まず3つの事件 ── 専門家でもやらかしている
事件1:弁護士が架空判例6件で5,000ドル制裁(米・2023)
ニューヨーク連邦地裁の航空事故損害賠償訴訟(Mata v. Avianca)で、原告側の Steven Schwartz 弁護士が ChatGPT に「類似判例を教えて」と相談しました。出てきた6判例。すべて存在しない判例だった。
問題はその後。裁判官が「コピーを出して」と命じた時、Schwartz 弁護士はまた ChatGPT に「これらの判例の本文をくれ」と頼んで、AI に偽の判例本文まで書かせて提出した。
結果:弁護士2名に5,000ドルの制裁、判事への謝罪文郵送命令、関係する各裁判官への通知。法律事務所 Levidow Levidow & Oberman は信用も失った。
「専門家だから安全」が崩れた最初の象徴的事件です。
事件2:Air Canada チャットボット虚偽案内→会社責任確定(カナダ・2024)
祖母の葬儀のため航空券を購入した Jake Moffatt さんが、Air Canada のチャットボットに「忌引運賃の申請方法」を質問。チャットボットは「搭乗後90日以内に申請可能」と回答した。実際の規定は「事前申請必須」。
申請が拒否されたので Moffatt さんが裁判を起こしたところ、Air Canada は「チャットボットは別法人で、会社は責任を負わない」と抗弁。裁判所は一蹴して、合計812カナダドル(差額650.88ドル + 利息36.14ドル + 手数料125ドル)の支払いを命じた。
これで「AI の出力 = 会社の公式案内」が判例として確定。チャットボット導入企業の責任設計が変わった事件です。
事件3:Apple Intelligence が BBC ニュース誤要約(米・2024)
2024年12月、Apple Intelligence の通知要約機能が、BBC ニュースの見出しを「Luigi Mangione shoots himself(容疑者が自殺)」と要約して iPhone ユーザーに配信しました。実際は容疑者は逮捕されただけ。
BBC が公式に抗議、CNN や The Register も連続報道、2025年1月に Apple は機能を一時停止しました。
iPhone ユーザー全員に届く規模の誤情報。「ニュース要約 AI を信じて、そのまま二次拡散」のリスクが現実化した事件です。
この3つに共通するのは:
- もっともらしい嘘(文章として違和感がない)
- 専門家でも検証を怠ると気づけない
- 使った人(弁護士・会社・配信プラットフォーム)が責任を取る
「AI が間違えたから AI のせい」では済まない。最終的に責任を負うのは出力を使った人 です。
ハルシネーションは「ランダム」じゃない ── 嘘の出やすい7型
ここからが本題。
AI の嘘は、実はランダムには起きません。起きやすい質問の型 があります。覚えるのは7つだけ。
| # | 型 | 例 | 警戒度 |
|---|---|---|---|
| 1 | 固有名詞詰め込み型 | 「○○大学の田中教授の論文を要約して」 | 🔴 |
| 2 | 数字ピンポイント型 | 「2024年の日本のEC市場規模は?」 | 🔴 |
| 3 | 引用要求型 | 「○○の判例・条文・名言を引用して」 | 🔴 |
| 4 | マイナー専門領域型 | 地方条例・社内固有用語・ニッチ業界用語 | 🟠 |
| 5 | 最新情報型 | 「今月の○○の動向は?」 | 🟠 |
| 6 | 誘導前提型 | 「○○は効果があるとされていますが、根拠は?」 | 🟠 |
| 7 | 曖昧丸投げ型 | 「○○について教えて」(前提条件なし) | 🟡 |
逆に 安全な型 もあります:
- 一般教養(公知の歴史・科学の基礎)
- プログラムコード(実行で検証できる)
- 文章校正・翻訳(自分で読んで判断できる)
- 構造化作業(箇条書きにして・要約して・整理して)
データで見ると、引用に関しては ChatGPT-3.5 で 55%、GPT-4 でも 18% が捏造 されているという研究報告があります(Nature Scientific Reports 2023)。「優秀なモデルなら安全」も成り立たない。
AI の「自信なさげなサイン」5個
質問の型と並んで、出力側にも警戒すべきサインがあります。
- 「一般的には〜と言われています」「諸説ありますが〜」
- 「〜と思われます」「〜の可能性があります」
- 同じ内容を言い換えて繰り返す(中身を盛れない時の挙動)
- 出典を求めると、URL が壊れている or 架空のもの
- 「正確な情報については専門家にご確認ください」と最後に逃げる

これらが1つの出力に複数出てきたら、その出力ブロックは保留扱い。
逆にもっと危険なのが:断言調 + 具体的固有名詞 + 数字 の組み合わせ。「自信ありげな捏造」が一番怖い。冒頭の Mata 事件はまさにこの型でした。「具体的な判例番号と判事名と年月日が並んでいる」── 弁護士ですら一瞬で信じてしまった。
たった1つの方法 ── 固有名詞・数字・引用を Google で照合
ここからが結論です。
業界標準が、完全にこの1つに収束しています:
- Anthropic(Claude を作っている会社):「引用を先に出させて、元文書と照合する」を公式に推奨(quote-first)
- OpenAI(ChatGPT):ChatGPT に Search / Browse / Deep Research を統合し、外部ソース照合を製品レイヤに組み込んだ
- NIST AI RMF(米国立標準技術研究所・2024年7月公開のガイドライン):**「外部検証」**を組織レベルで要求
つまり「AI ベンダー自身が、自分の AI を信用していない箇所」── それが 固有名詞・引用・数字 です。ここだけ Google で照合する。
なぜこの1つで十分か
理由1:誤りやすい箇所を集中的に叩ける 人名・年号・URL・数字は最も誤りやすく、しかも文章全体の信頼度を支える要石です。ここが嘘なら、全体が崩れる。
理由2:Lv1 の認知負荷が最も低い 「答え全体の正誤」は技術ゼロの初心者には判定できません。でも「この人名は実在するか」「この URL は開けるか」「この数字は出典と一致するか」── これは Google 検索1回で済む。
理由3:追加コストゼロ Plus 課金もツールも要りません。ブラウザの Google タブを1つ余分に開くだけ。
やってはいけない検証方法 4つ
「素朴に思いつく検証法」のうち、実は危ないものが4つあります。
| やってはいけない | なぜ |
|---|---|
| ❌ 「同じ質問を別 AI に聞く」だけで判定 | 別 AI も同じ Web データで学習している場合、同じ嘘を共有する。「両方同じだから正しい」は致命的な誤認 |
| ❌ AI に「自信は何%?」と聞く | LLM は 自信過剰傾向(複数論文で指摘)。自己申告は信用できない |
| ❌ Perplexity / Bing の引用リンクをクリックせず信用 | 「hallucinated citation」(存在しない URL・論文)が一定割合で発生 |
| ❌ 文章全部を疑って毎回検証 | 続きません。続かない検証は意味がない |
特に1つ目の「クロスチェック」が罠です。直感的に「2つの AI で答えが一致すれば正しい」と思いがちですが、両モデルが同じ Web データで学習している以上、同じ間違いを両方が言うことが普通にあります。
業界の検証で「クロスチェック単独はダメ」と明示されているのはこのためです。
4ステップ実行手順(コピペで保存)
ここまでの内容を、毎回使える形に整えました。
Step 1【質問前】
「これは7型のどれかに当てはまるか?」を判定
→ 当てはまるなら、最初から検証前提で使う
Step 2【出力後】
固有名詞・数字・引用を蛍光ペンで囲む(脳内でOK)
Step 3【検証】
囲んだ箇所だけ Google にコピペして1点確認
- 人名・組織名 → 公式サイトで実在確認
- 数字 → 出典ページの数字と一致するか
- 引用 → 引用元の文書に実在するか
Step 4【判断】
1つでも不一致なら、その出力ブロックは捨てる
(文章全部ではなく、該当箇所だけ捨てればOK)ポイントは「全文検証しない・固有名詞と数字と引用だけ」。Lv1 が挫折しない最小単位に絞っています。
「全部疑え」は無理ですが、「3種だけ確認しろ」なら続きます。
大学・公的機関のガイドラインも同じことを言っている
念のため業界全体の着地点を確認しておくと、独立した複数の機関が同じことを言っています。
- 東京都市大学 学生向け生成AI ガイドライン(2024):「生成AI は理路整然とした文章の中に間違った情報が混ざる。ファクトチェックは必ず人の手で行うこと」
- 大阪大学 全学教育推進機構:「複数の情報源で事実確認や裏付け調査を行い、内容を検証することが必須」
- IPA テキスト生成AI 導入・運用ガイドライン(2024年7月):「生成物の確認は利用者の責任」
「人の手」「複数の情報源」「利用者の責任」── 業界全体が同じ着地点を示している。「AI に任せきりはダメ」は、すでにコンセンサスです。
シリーズの締めくくり
5本シリーズ「AI を仕事で使う前に知っておくこと」の振り返り:
| 弾 | 主題 | 守る対象 |
|---|---|---|
| 第1弾 事故対応3手順 | 入れちゃった後 | 自分の個人情報 |
| 第2弾 個人利用20ケース早見表 | 入れる前の境界線 | 自分のプライバシー |
| 第3弾 漏れ方5つの経路 | なぜ漏れるか | 入力経路の理解 |
| 第4弾 仕事編5問テンプレ | 会社で使う前 | 会社・顧客・取引先 |
| 第5弾(本記事) | 出てくる答えを信じる前 | 自分と相手の判断 |
5本そろえば、AI を怖がりすぎず、使いすぎずの中庸ポジションに立てます。完全に避ける必要はないし、無防備に使う必要もない。
入る前・出る前の両方に、確認の習慣を1つだけ持つ。それで事故の9割は防げます。
まとめ
- AI の嘘は「ランダム」じゃなく、7型の質問 で起きる
- 自信なさげなサイン5個を覚える・自信ありげな捏造が最も危険
- たった1つの方法 = 固有名詞・数字・引用を Google 1検索で照合
- やってはいけない検証法も知っておく(クロスチェック単独・自信%・引用クリックなし・全文検証)
- 全文検証しない・3種だけ抜き出して照合 が初心者の現実解
明日のメール返信から、Google タブを1つ余分に開く習慣だけで、ハルシネーション事故の9割は防げる。これがシリーズの最後のメッセージです。
難しいですよね。でも目を逸らすとあっという間に被害に直結する。便利だけどそれだけ攻撃力が高いのも事実です。
次に読むなら
シリーズの他の4本:
- 生成AI に個人情報を入れちゃった どうする? ─ 事故ったあとの3手順
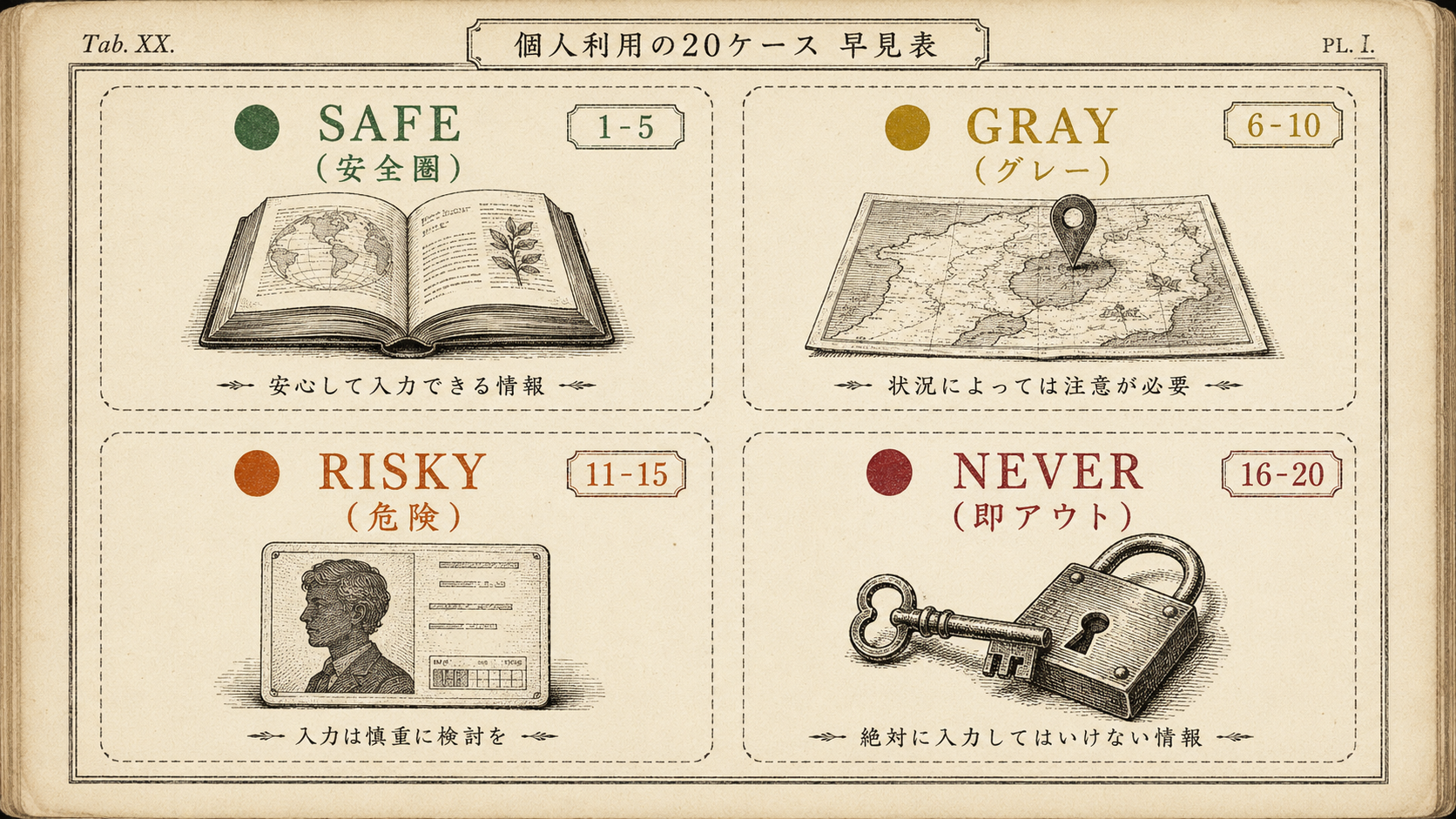
- 生成AI 入れていい? 個人利用の20ケース早見表 ─ 個人利用の線引き
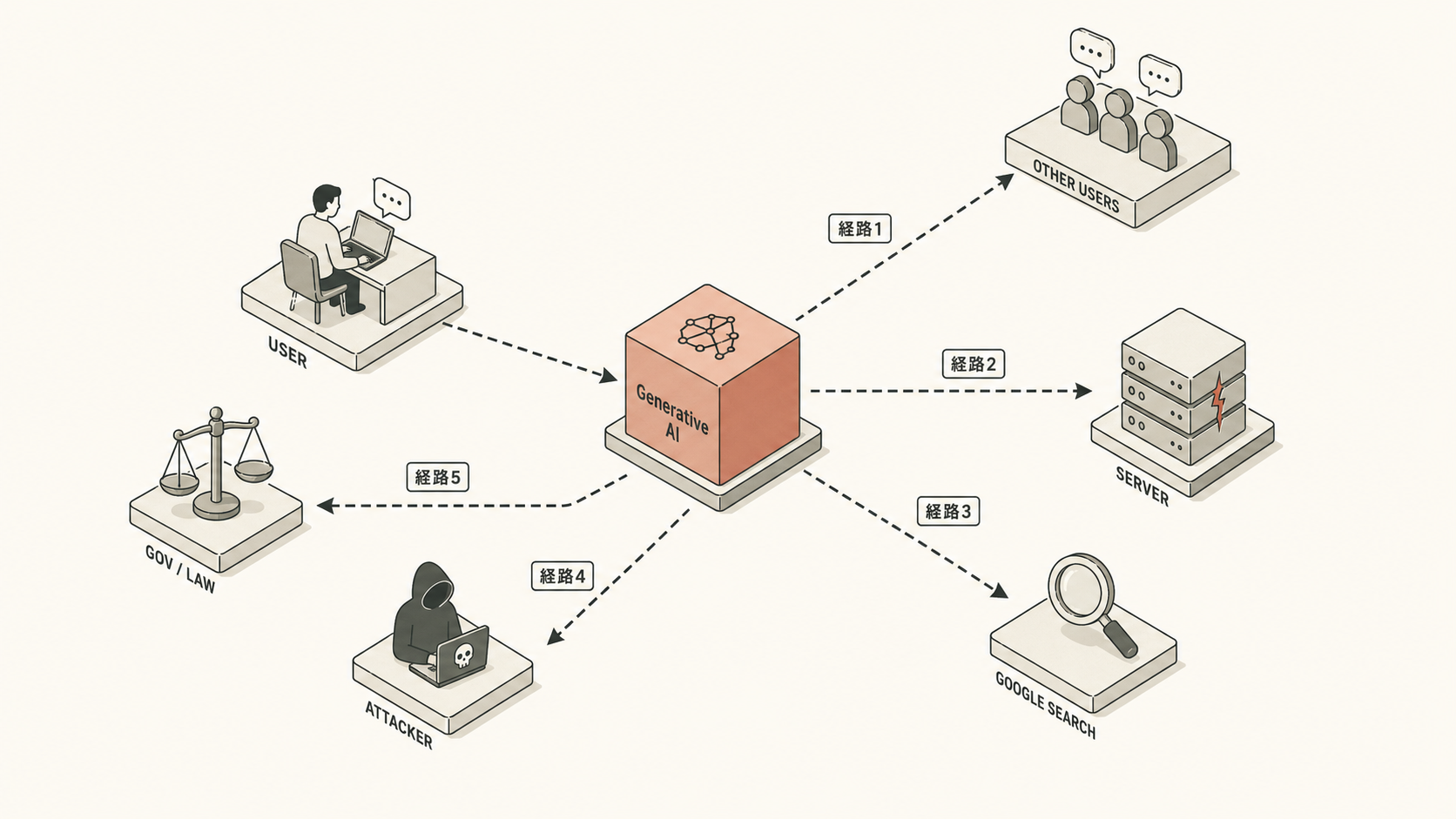
- 学習だけじゃない 生成AI に入れた情報の漏れ方5つの経路 ─ なぜ漏れるか
- 会社で生成AI を使う前に、上司に確認したい5つの質問 ─ 仕事編
参考にした一次ソース(2025年時点)
事件(一次〜準一次):
- Mata v. Avianca:Justia 判決原文 / Wikipedia
- Air Canada:CBC News 報道
- Apple Intelligence:CNN Business 報道 / The Register
検証法(業界標準):
- Anthropic:Reduce hallucinations 公式
- OpenAI:Why language models hallucinate
- NIST AI RMF:Generative AI Profile
研究:
日本のガイドライン:
仕様は頻繁に変わります。一次ソースの確認日を併記しているのは、いつ時点の情報かを明示するため。読んでくれた人が、自分の領域の最新情報を確認しに行くための補助線 として使ってください。