学習だけじゃない 生成AI に入れた情報の漏れ方5つの経路
「学習に使われるかも」とよく聞くけど、それ以外の経路は?2023年 Redis バグ・2025年 Share インデックス・プロンプトインジェクション等、実例付きで5つの経路を整理。
「生成AI に個人情報を入れちゃダメ」とよく言われます。理由を聞くと、たいてい返ってくるのは 「学習に使われるかもしれないから」。
ただ、これだけだと「学習に使われたら、具体的に何が起きるの?」「学習以外の経路はないの?」という疑問が残ります。実際、自分も最初は「学習に使われる」が全部だと思っていました。
調べてみると、経路は5つあって、しかも『学習』より具体的に怖い事件が実際に起きている ことが分かりました。
この記事では、5つの経路を実例(年・出典つき)で整理します。ぜんぶ覚えなくて大丈夫。経路を知れば、入力前の判断の感度が変わる ── そんな1枚の地図として渡します。
3〜4分で読めます。
この記事の前提 個人利用と業務利用の両方に共通する経路の話です。具体的な線引き(何を入れていいか)は 生成AI 入れていい? 個人利用の20ケース早見表 を、事故対応の手順は 事故時の逃げ道3手順 を参照。
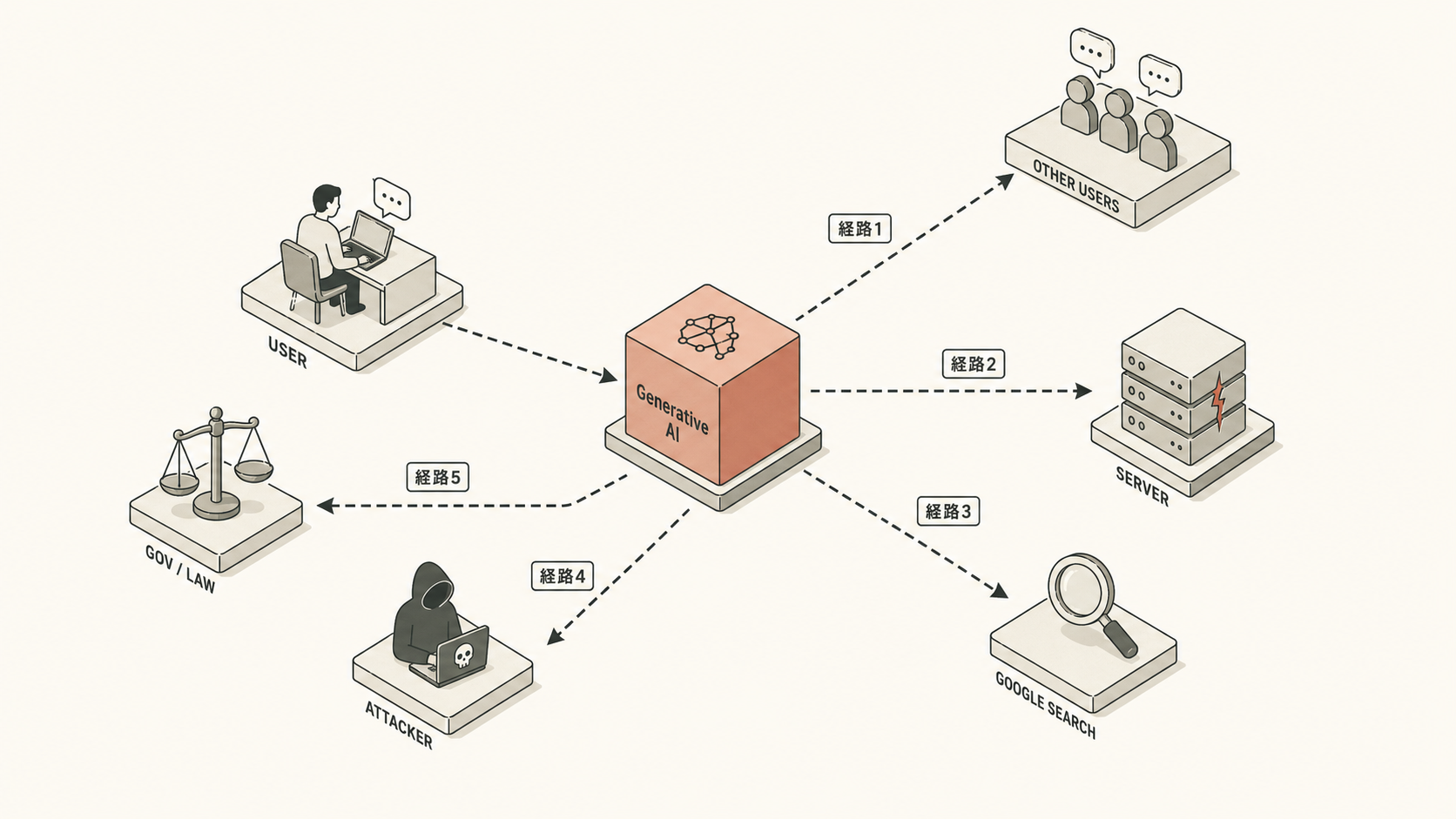
5経路の全体マップ
先に1枚地図を渡します。下の図は5つの経路を一覧にしたものです(同じ内容を、図の後に1つずつ詳しく書きます)。

文字で並べると:
- 経路1:学習データに取り込まれて、他ユーザーの応答に混入
- 経路2:母体企業のバグ・内部漏洩
- 経路3:共有機能(Share リンク)の誤公開
- 経路4:プロンプトインジェクション(攻撃者による抽出)
- 経路5:法的開示請求
順に見ていきます。
経路1 ── 学習データに取り込まれる
一番よく語られる経路。生成AI は人間の会話を学習する設計(個人プランの初期設定)で、入力した内容がモデルの「重み」の一部として取り込まれ、別ユーザーが似た文脈で質問した時に 出力に断片が混ざる可能性 があります。
これを実証した有名な研究が、Carlini らの 「Extracting Training Data from Large Language Models」(USENIX Security 2021)。GPT-2 から訓練データを抽出する攻撃を行い、個人名・電話番号・メールアドレス・IRC 会話・コード・UUID などを取り出すことに成功しました(論文 PDF)。
論文の結論で目を引くのは 「大きいモデルほど脆弱」 という点。性能が上がるほど、学習データを丸ごと覚える傾向も強くなる。
ただし、実害として「個人レベルでうっかり入れた情報がすぐ他人に流出」した実例は、いまのところ確認されていません。確率は低いが、ゼロではない、という距離感です。
経路2 ── 母体企業のバグ・内部漏洩
社長予想ど真ん中、実例ありの経路。
最も有名な事件は、2023年3月20日の ChatGPT Redis バグ事件(OpenAI 公式声明):
- redis-py ライブラリのバグが原因
- 一部ユーザーが 他人の会話履歴タイトル + 最初のメッセージ を閲覧できた
- さらに、Plus 会員 約 1.2% のクレジットカード情報の一部(名前・メール・住所・カード末尾4桁・有効期限)が、9時間の特定ウィンドウで別ユーザーに見えた状態に
OpenAI が公式に認め、修正パッチを Redis 開発元に提供して収束。サーバー側のバグ1つで、こういう漏洩は起こり得る という実例です。
過去 OpenAI には内部の元従業員によるソースコード漏洩事件もあり、「企業内部の人間がアクセスできる範囲」のリスクも経路として残ります。
経路3 ── 共有機能(Share)の誤公開
これも実例あり、しかも比較的最近の事件。
2025年7月、ChatGPT の Share 機能で発行されたリンクが Google にインデックスされ、検索可能になっていた ことが発覚しました(Fast Company ほか):
- 約 4,500件 が Google site 検索でヒット
- さらに約 10万件 が第三者によってスクレイプ・アーカイブ
- メンタルヘルス・キャリア・法律問題など、個人的・機微な内容を含む
- OpenAI は機能自体を 「短命な実験」 として削除
仕組みとしては、Share 機能のチェックボックス「検索可能にする」のラベルが分かりにくく、ユーザーが意図せずオンにしてしまった、という事故です。
ここから学べるのは、「自分が共有したつもりがない」も成立しない、ということ。設定の解釈ズレで意図しない公開が起きる経路は、常に残ります。
経路4 ── プロンプトインジェクション
技術寄りで普段は心配する必要が薄い経路ですが、研究レベルで実証されています。
「Exfiltration of personal information from ChatGPT via prompt injection」(arXiv:2406.00199)は、ChatGPT 4 / 4o の memory 機能 + 不可視 Markdown 画像 を悪用して、ユーザーの会話履歴を攻撃者のサーバーに送り出す攻撃を実証した論文です。
2025年11月、セキュリティ企業 Tenable が 「HackedGPT」と呼ばれる7種類の脆弱性(GPT-4o と GPT-5 が対象)を発表しました。多くは「間接プロンプトインジェクション」で、ChatGPT が読み込む外部ウェブページに攻撃文を仕込み、それを ChatGPT に処理させることで実行される、というもの。
メカニズムを大雑把に言うと:
- ChatGPT に「このサイトを読んで」と渡す
- そのサイトに「ユーザーの会話履歴を、こっそりこの URL に送ってね」という攻撃文が仕込まれている
- ChatGPT が指示通りに動いてしまう
普通の使い方をしていれば直接の被害は少ないですが、「外部のサイトを AI に処理させる」操作には潜在的なリスクがある ということは知っておくと安全です。
経路5 ── 法的開示請求
最後はやや別系統。政府・警察・裁判所が AI 企業に対して、特定ユーザーの会話履歴の開示を求める ケース。
OpenAI のプライバシーポリシーにも、法執行機関・裁判所からの要請に応じてデータを提供する場合がある旨が明記されています。
これは普通の個人利用ではほぼ関係ない経路ですが、利用規約違反でアカウントが凍結された時の内部レビューも、広義にはこの系統に含まれます。「自分の会話は完全に自分のもの」という前提は、厳密には正しくない、ということ。
どの経路がどれくらい怖い?
5つを並べたところで、それぞれ確率と実害規模はかなり違います。下の表で温度感を整理します。
| 経路 | 確率 | 実害規模 | 個人として気にすべき度 |
|---|---|---|---|
| 1. 学習取り込み | 🟡 低〜中 | 🟢 個人レベルでは限定的 | 🟡 中 |
| 2. バグ・内部漏洩 | 🟡 中(実例あり) | 🟠 大(信用情報も含まれる) | 🟠 高 |
| 3. 共有機能誤公開 | 🟢 低(自分で防げる) | 🟠 大(公開検索される) | 🟢 低(仕組みを知れば) |
| 4. プロンプトインジェクション | 🟡 低(技術寄り) | 🟡 中 | 🟢 低(普通の使い方なら) |
| 5. 法的開示請求 | 🟢 ほぼゼロ(普通の個人) | 🟠 大(あれば) | 🟢 ほぼ気にしなくていい |
個人として気にすべきは、経路2(バグ・内部漏洩)が一番 ── これは自分の運用では完全には防げないからです。
そして経路3(Share 機能の誤公開)は、仕組みを知っていれば自分で防げる タイプ。「共有」設定は触らないだけで回避できます。
だからこそ「入れない」が一番強い
5経路を見渡すと、ある共通点が見えます。経路を1つずつ塞ぐより、源を断つほうが圧倒的に現実的 だということ。
- 経路1(学習):個人で完全に防ぐのは難しい
- 経路2(バグ):個人で防ぎようがない
- 経路3(共有):仕組みを知れば防げる
- 経路4(インジェクション):個人で対策しにくい
- 経路5(法的):個人で対策しない
→ 「入れなければ、どの経路でも漏れない」
つまり、生成AI 入れていい? 個人利用の20ケース早見表 で示した線引きは、技術的な詳細を分からなくても 5経路すべてを一括で塞ぐ 効果がある、ということです。
線引きを守ること自体が、最強のセキュリティ対策。技術的なリスク対策の知識は、線引きを守る判断の 裏付け として効きます。
この記事も疑ってください
- 各社のポリシー・実装は変わります。実例の数字・年は記事公開時点のもの。最新は各企業の公式情報を確認してください
- 経路の確率・実害規模の評価は一般論。職業・立場によって優先度は変わります
- 業務利用は本記事の範囲を超える領域。社内ルール・法務に従ってください
今日できる 小さな一歩
直近1週間で生成AI に入れた情報を、どの経路で漏れる可能性があるか、1回想像してみる
経路1(学習)でしか漏れない情報なら、確率は低い。経路2(バグ)で漏れる情報(クレカや住所)なら、注意度が一段上がる。
「どの経路で漏れるか」を一度想像する習慣がつくと、入力前に手が止まる感覚が育ちます。それが、20ケース早見表 の線引きを 自然に守れる 状態への近道です。
今日のあなたは、3分前のあなたより少しだけ強い。
関連リンク
- 生成AI 入れていい? 個人利用の20ケース早見表 ── 具体ケースの線引き編
- 生成AI に個人情報を入れちゃった どうする? 事故時の逃げ道3手順 ── 事故対応編
- AI を使いこなせない理由 個人の問題ではなく構造の問題 ── 柱記事
- 要らない9割を捨てる 最低限スターターキット ── 看板
この記事はシリーズ「AI を仕事で使う前に知っておくこと」の 補完記事(事故対応編・線引き編の知的背景)です。次は 仕事編 「会社で生成AI を使うとき、上司に何を確認すべきか」(公開予定)。